Verifiable Extraction in The Graph
In this article we discuss the methodology that Semiotic Labs uses to verify that blockchain data extracted from some source matches the history of the chain.

The Graph is a decentralized protocol organizing blockchain data for easy access. Indexers maintain this organized data and provide a way for developers, dapps, and data analysts to query the data they need.
In order to provide accurate results and avoid slashing, an Indexer should ensure that the data they are using to respond to queries is correct and reflects the recorded history of the protocol from which it was derived. Here we discuss Verifiable Extraction, the process of verifying that data pulled from a blockchain accurately reflects the chain’s ledger.
Sources of Information
An Indexer can retrieve, or extract, blocks from a chain for indexing and querying services by different means. These include direct access to an archive node, file sharing among Indexers, or pulling from a central repository of information.
Below we will discuss what it means for blockchain data to be verifiable, how verification can be carried out, and how Semiotic’s veemon project provides source code in Rust to verify Ethereum blocks.
Verifiable Data: Integrity and Authentication
When Alice shares a file with Bob, how can Bob trust that the file has not been altered in transit, and that he has the same information that Alice has? Bob needs to verify the integrity of the information. Alice makes a claim involving the file’s contents and sends this claim to Bob along with the file. Bob can reconstruct the claim from the information he receives and verify that it matches the one Alice sent.
A useful claim is easy to reconstruct and verify, and should only correspond to the message from which it was constructed (in practice, we cannot always guarantee this, but it can be assured with high probability). In the context of SNARKs, such a claim is called a commitment.
Example: Hash Functions
A cryptographic hash function is practical for verifying information integrity. This is a function with the following properties:
- The output of the hash function (which we call the hash) is a fixed size, regardless of the size of the input.
- It is easy to compute the output of the hash function, but it is difficult (i.e., computationally infeasible) to find an input for a given output (it is a one-way function).
- Given an input-output pair, it is difficult to construct another input which gives the same output. Moreover, it is difficult to find two inputs which give the same output.
A simple example of an integrity verification scheme which typically uses a hash function is a checksum. Checksums are commonly used to check for errors in downloaded software.
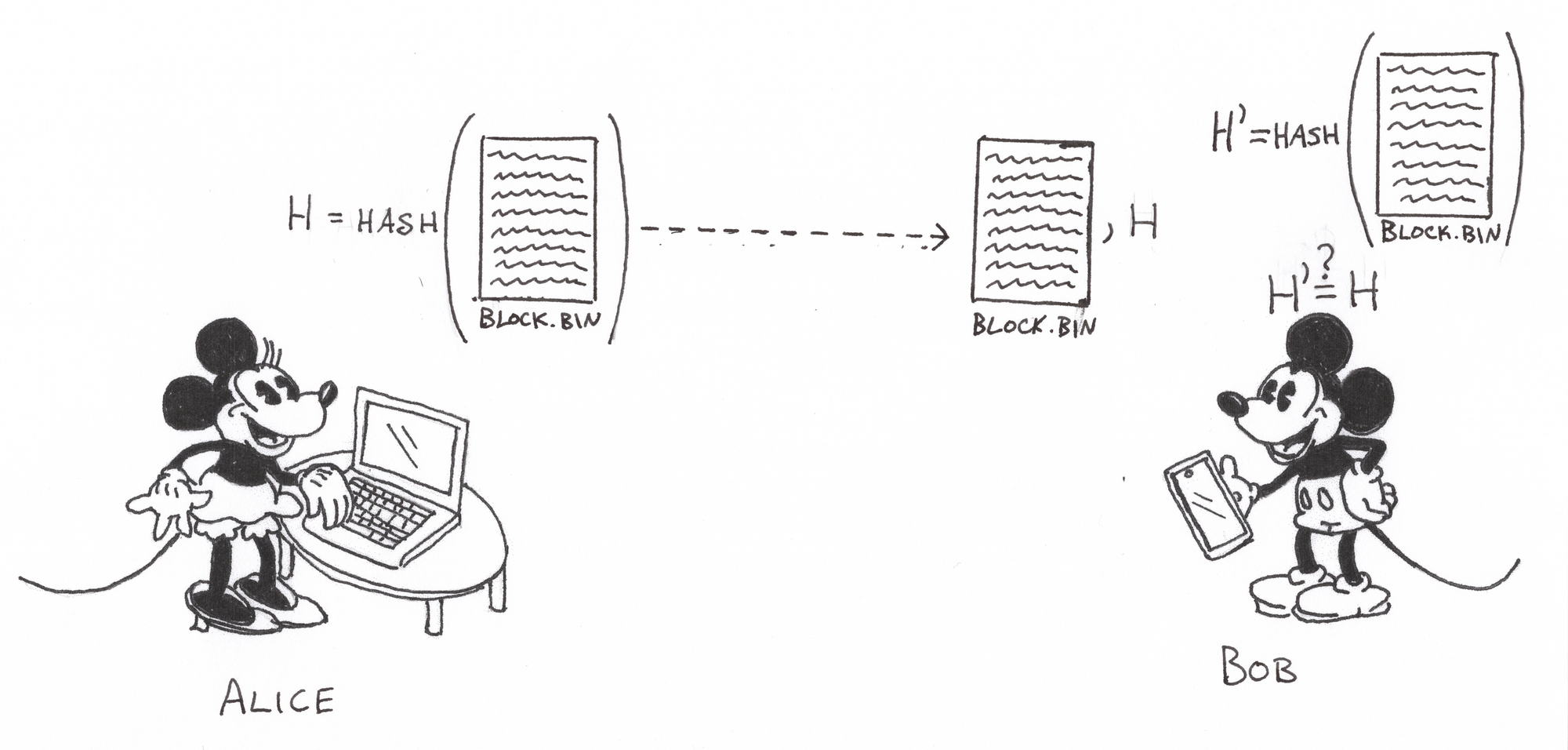
Returning to our scenario above, Alice can compute the hash of the file (this is her commitment to the data) and send it along with the file to Bob. Bob receives the file and the hash. He easily computes the hash of the file, compares it to the one Alice sent, and finds that the hashes match. Since it is improbable that an altered file would produce the same hash as the original, Bob can gain some level of trust that the contents of the file are correct.
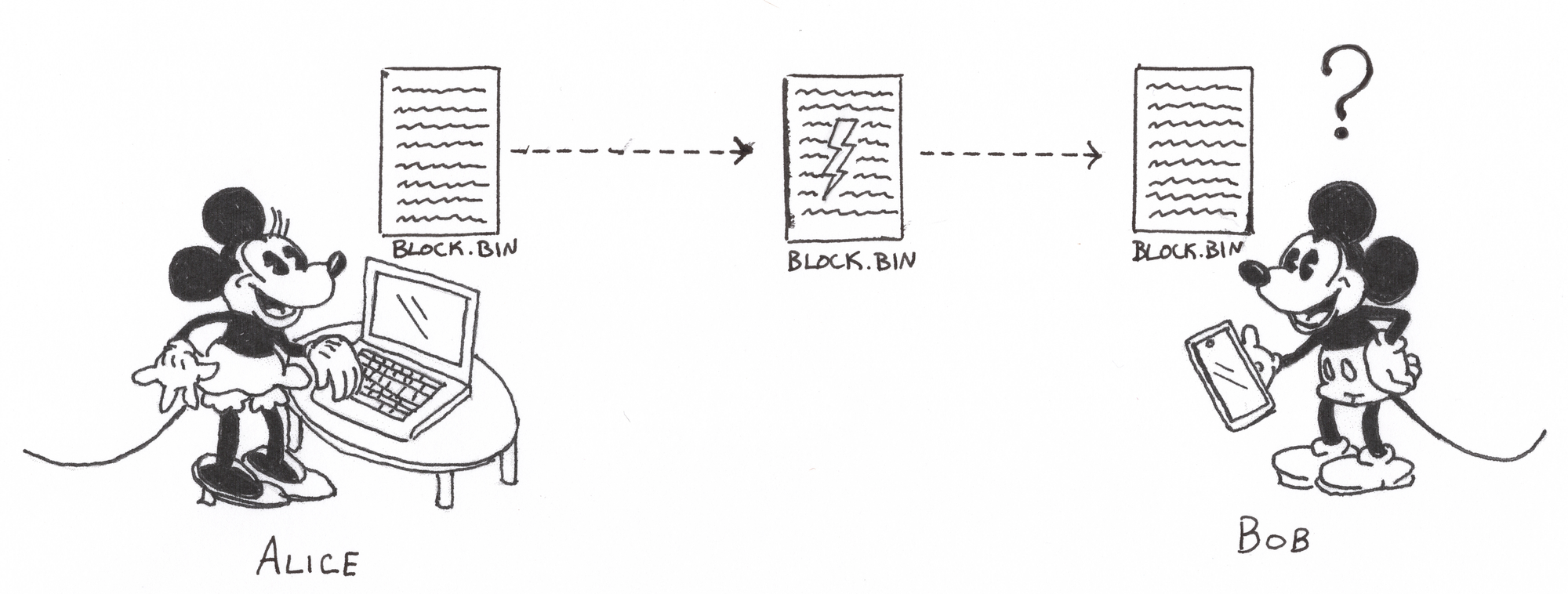
What is to prevent an adversary, Eve, from intercepting the file and altering it? She can rewrite the contents of the file, calculate a new commitment using the altered content, and write the new commitment into the erroneous file to be sent to Bob. He will then perform the check and conclude that the data is correct. To solve this problem, we can use an additional layer of authentication to ensure that the file actually came from Alice. In the context of data exchange as in this example, authentication is typically accomplished through the use of digital signatures.
With this Alice and Bob example, we have illustrated two necessary components of verifiable data:
- Integrity: The data is correct.
- Authentication: The data came from a trusted source.
Let’s examine how blockchain data can be verified using these characteristics.
Integrity: Verifying the Contents of the Block
An Indexer using information from a blockchain could extract that information by various means, including from a shared file, a data repository, or by direct RPC request. Here we focus on a specific file format used to store blocks.
StreamingFast’s Firehose enables the creation of binary flat files (https://github.com/streamingfast/dbin) which can be easily shared and archived among Indexers. These flat files generalize execution blocks from multiple chains via Google Protocol Buffer (Protobuf) definitions. Blocks can also be streamed directly from a Firehose-enabled blockchain node.
The benefits of using verifiable data—such as Firehose flat files—as a source for Indexers include the following.
- Indexers can share files without needing to trust each other as repositories of information, since they can verify the files’ contents. By sourcing data from another Indexer rather than syncing the full blockchain history via an archive node, an Indexer can reduce the time it takes to start indexing a Subgraph.
- An Indexer needs to ensure that the data it provides to an end user has integrity and is consistent with the history of the blockchain.
- Historical blockchain data must be maintained for developers who require it (e.g. to assess long-term trends). Flat files can be used to circumvent history pruning (e.g. as specified in EIP-4444) as an archived source of truth.
In order for blocks to be verifiable, they should include commitments to the data (e.g., transactions, receipts) that they contain. Let’s look at an Ethereum block as an example. A block contains a record of what happens on the chain via transactions and receipts. If an Indexer is using this information to respond to a query, they need to verify that the information is correct. The block contains commitments to the transactions and receipts, called the transactions root and the receipts root, respectively. As with Alice’s file and hash-commitment above, the Indexer can calculate the transactions root using the transactions recorded in the block. If the calculated version matches that recorded in the block, he can trust that the transactions laid out in the file correspond to the recorded commitment.
Following is an example of a Firehose Ethereum block definition. The header contains the transactions root and receipts root. The transactions and receipts are derived from transaction_traces.
message Block {
bytes hash = 2;
uint64 number = 3;
uint64 size = 4;
BlockHeader header = 5;
repeated BlockHeader uncles = 6;
repeated TransactionTrace transaction_traces = 10;
repeated BalanceChange balance_changes = 11;
enum DetailLevel{
DETAILLEVEL_EXTENDED = 0;
DETAILLEVEL_BASE = 2;
}
DetailLevel detail_level = 12;
repeated CodeChange code_changes = 20;
repeated Call system_calls = 21;
reserved 40;
reserved 41;
reserved 42;
int32 ver = 1;
}
The transactions (resp., receipts) root is calculated by constructing a Merkle tree, which uses a hash function to incorporate information from a group of transactions (the leaves) into a single hash output (the root). Any change in a recorded transaction will result in a change to the commitment. Another aspect of Merkle trees which we will use later is that one can construct a proof to show that a given leaf was part of the set used to calculate the corresponding root.
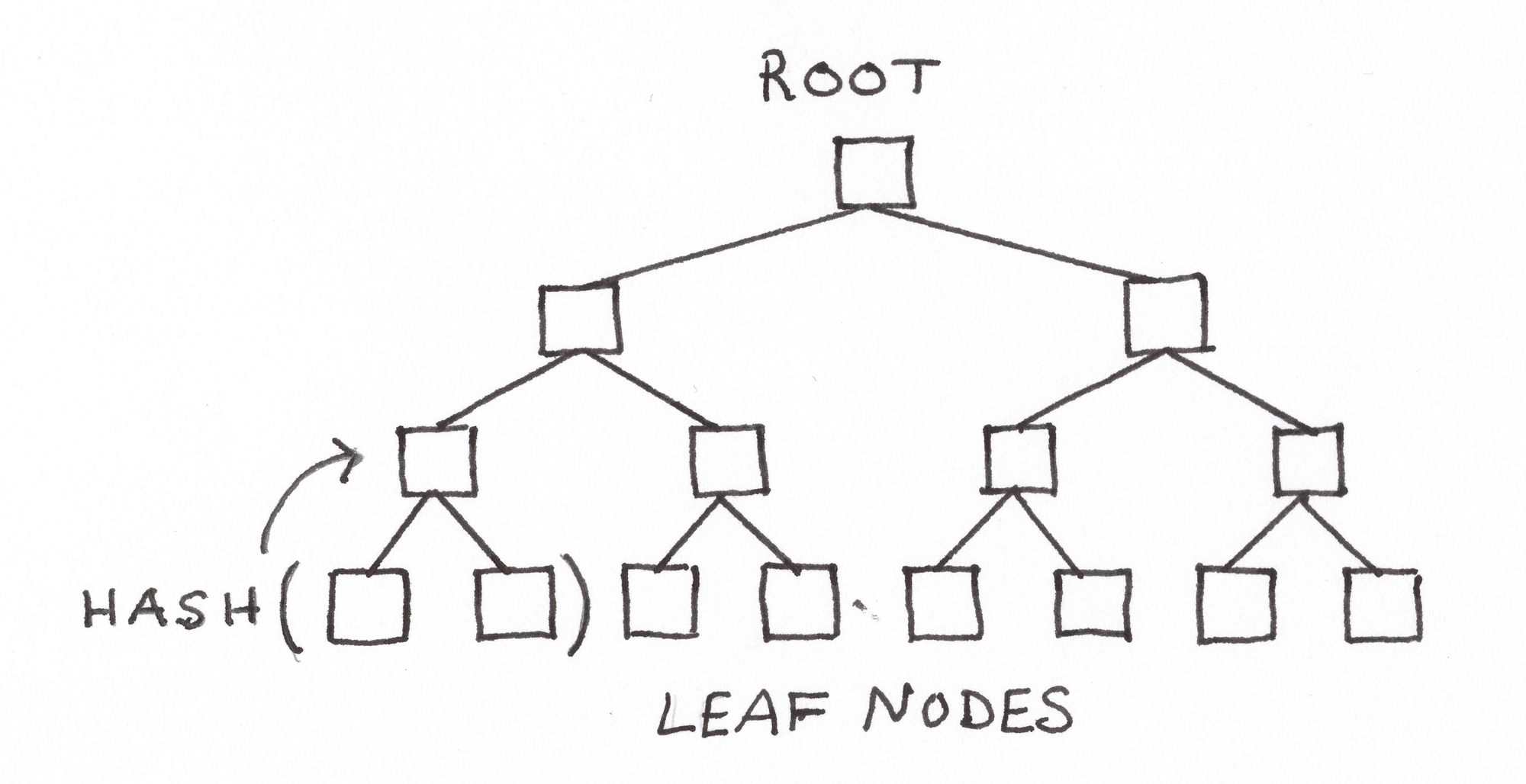
Furthermore, each block contains a hash of block header information, including the transactions root and the receipts root. By reconstructing this block hash, the Indexer can ensure that the transactions root (and by extension, all of the transactions) is self-consistent with the block itself.
Not every chain uses transactions and receipts roots as Ethereum does. Some blocks just contain a block hash which incorporates certain information in the block. The transactions/receipts roots are a good way to verify the transaction and receipt content, but the primary commitment to the data in the block is the block hash. We will call information that is associated with a commitment committed data. Any information which an Indexer uses to serve up a query result should be committed data.
This illustrates our first requirement for verifiable block data:
1. The contents of the block should be associated with a commitment that can be verified.
Authentication: Verifying the Source of the Block
By verifying the contents of the block (e.g., transactions and receipts), an Indexer can ensure that a block is self-consistent. Let’s say Indexer Bob has received a file with an Ethereum block from Indexer Alice. Bob has verified that the transactions and receipts are valid, that is, the transactions root and receipts root check out, and the block hash matches his own reconstruction as well. Bob can trust that the information is laid out accurately and there wasn’t any data corruption in transmission of the file. But what is to prevent Alice from changing or omitting a transaction in the original block, recalculating the transactions root and block hash based on this erroneous information, and writing the altered data and commitment into the file? When Bob receives the changed block, everything will check out as it should. To address this issue, we need to verify that the block itself came from a trusted source. Our ultimate source of trust here is the blockchain ledger. We can compare the block to the historical record of the blockchain to make sure that it came from a trusted source. This is, in a way, authentication of the data in the sense that we are verifying its expected origin - the blockchain itself.
This leads to our second requirement for verifiable data:
2. The block can be shown to match the blockchain’s ledger.
Proof of Inclusion in the Chain’s History
Here we describe how we can prove that a pre-Merge Ethereum block is contained in the chain’s canonical history.
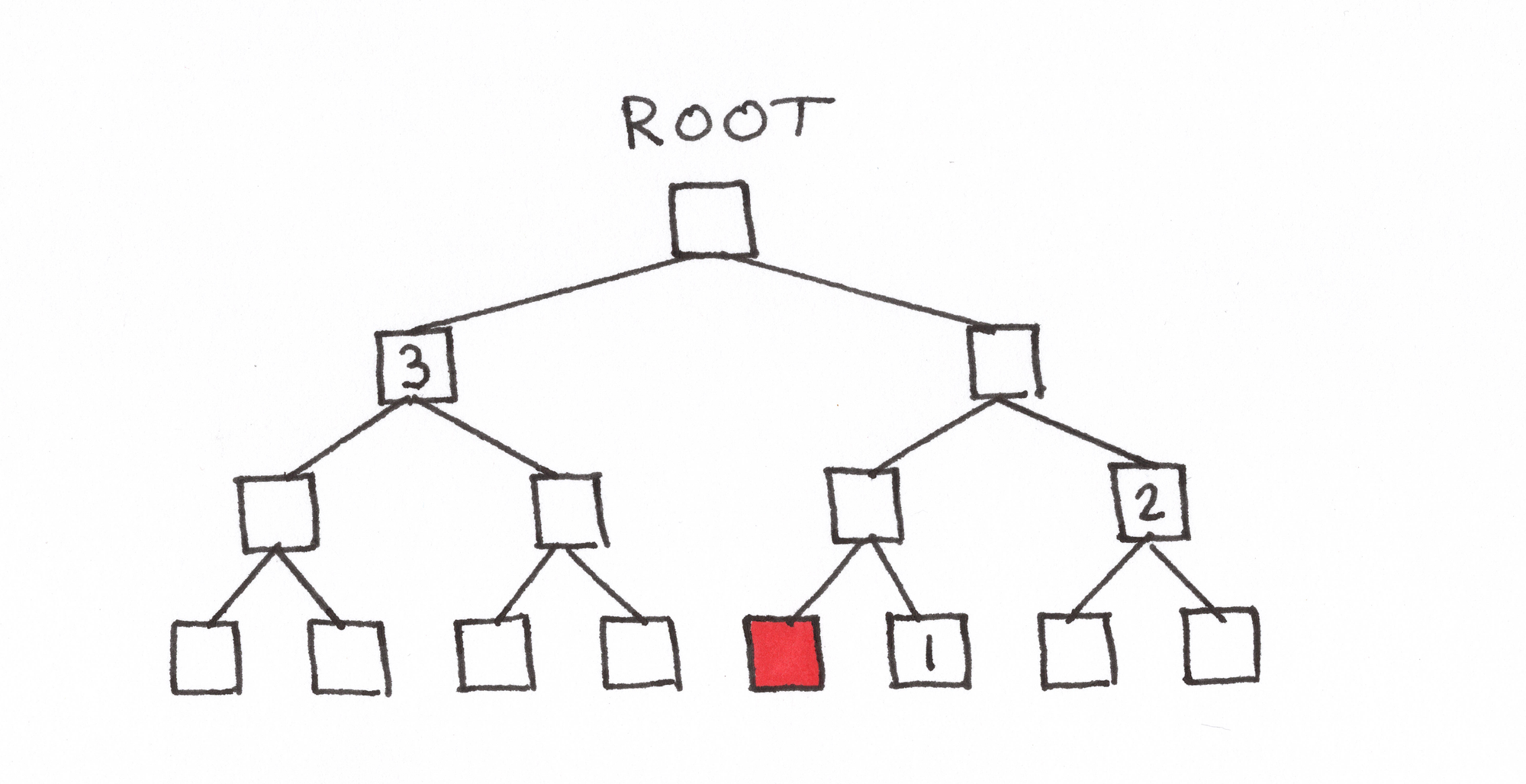
Similar to how there is a transactions root commitment to a group of transactions, we can construct a commitment to a group of block hashes. A group here is equal to 8,192 block hashes and is called an era. By calculating the root of a Merkle tree with these block hashes at the leaves, we create a commitment to this era.
A verifier compares this root to a trusted record of roots for all eras in the Ethereum history. The Portal Network maintains a record of these era-based roots called a Header Accumulator (this name comes from the fact that a block hash is effectively a hash of the block header, and entries can be accumulated as the number of eras increases).
Indexer Bob wants to make sure that the Ethereum block he received from Indexer Alice was really part of the chain’s canonical history. We discuss two ways this can be done.
In the first way, Bob does all of the work himself. He needs the full era of block headers (or at least block hashes) containing the block hash in question. These could be sourced from Alice as well. He uses this era to calculate the root of the corresponding Merkle tree and compares the result to this era’s entry in The Portal Network’s Header Accumulator. If it matches, he can trust that the block in question is part of the chain’s history. If the root does not match, then either the block is not accurate, or there is a problem with at least one of the other block hashes in the era. Bob is essentially checking all 8,192 block headers in the era by constructing this Merkle tree.
In the second method, Alice constructs an inclusion proof to show that the block she provided is in a given era, and Bob just needs to verify the proof. Alice has a full era of block headers which includes the one in question (perhaps she streams a full era of blocks at a time from Firehose for this purpose). She constructs the Merkle tree and root matching the ground-truth Header Accumulator entry. The inclusion proof gives specific nodes of the tree. Only someone with the full, accurate set of leaves (including the leaf in question) would be able to provide each step of this verification path. Bob can then use this information to calculate the root and compare it to the Header Accumulator himself.
veemon: Verifiable Extraction in Rust
Semiotic Labs maintains source code in Rust to perform verifiable extraction of Ethereum blocks. One can use the firehose-client repository to extract blocks from a StreamingFast Firehose-enabled Ethereum node. The veemon repository provides the capability to parse StreamingFast .dbin files containing Ethereum blocks, and to verify the content and history of pre-Merge and post-Merge blocks. Verifying the authenticity of post-Merge blocks is similar to the process described above, but we can take advantage of additional information associated with Beacon chain blocks as well.
As information from decentralized protocols is extracted by Graph Indexers and served to end users, it is important to ensure that the information is trustworthy. Indexers serving up blockchain records must be able to verify that the data is correct according to the consensus of the blockchain. In this article, we have laid out a general framework for verifiable blockchain data. For a block to be verifiable, the contents of the block should be associated with a verifiable commitment to ensure that they are correct, and the block can be proven to match the trusted history of the chain. Semiotic Labs provides tools to perform such verification for pre-Merge Ethereum blocks following the framework we have discussed in this article.